CVE-2017-1002101漏洞能让Kubelet创建的Pod挂载到宿主机中不允许挂载的目录,从而造成了逃逸。这听上去很不可思议,因为完全可以在PSP(Pod Security Policies)中限制Pod对主机目录的挂载权限。是的没错,我们可以通过PSP限制Pod只能挂载特定的安全目录,对于其他目录都不允许挂载。但是,至少在k8sv1.9.4版本之前,这种逃逸攻击都是可行的。其核心,就是Linux的软连接和k8s的volume subPath。
软连接不用说,说一下subPath。没创建一个volume,它就会挂载到宿主机中指定的目录,将这个目录称为hostPath。但是,如果希望让不同的Pod或者同一个Pod下不同的容器挂载到该volume下的不同子目录,怎么实现?答案就是subPath。以同一个LAMP Pod(Linux Apache Mysql PHP)下的不同容器为例,我们可以让整个Pod挂载到指定volume下,但是让mysql的工作目录挂载到该volume的mysql子目录下,让html的资源目录挂载到该volume的html子目录中。
apiVersion: v1
kind: Pod
metadata:
name: my-lamp-site
spec:
containers:
- name: mysql
image: mysql
env:
- name: MYSQL_ROOT_PASSWORD
value: "rootpasswd"
volumeMounts:
- mountPath: /var/lib/mysql
name: site-data
subPath: mysql
- name: php
image: php:7.0-apache
volumeMounts:
- mountPath: /var/www/html
name: site-data
subPath: html
volumes:
- name: site-data
persistentVolumeClaim:
claimName: my-lamp-site-data也就是说,一个Pod或是容器,具体挂载进宿主机下的哪个目录,是通过hostPath+subPath来决定的。当然,默认情况下subPath为空。
至于为什么subPath配合软连接可以让Pod挂载到权限之外的目录,就要从Kublet源码开始分析,深入了解一下创建Pod时,volume是如何创建和挂载的。
源码分析
Pod创建过程
这里使用的k8s版本为v1.9.3,git commit为d2835416544。比较老,因为这个漏洞比较早。
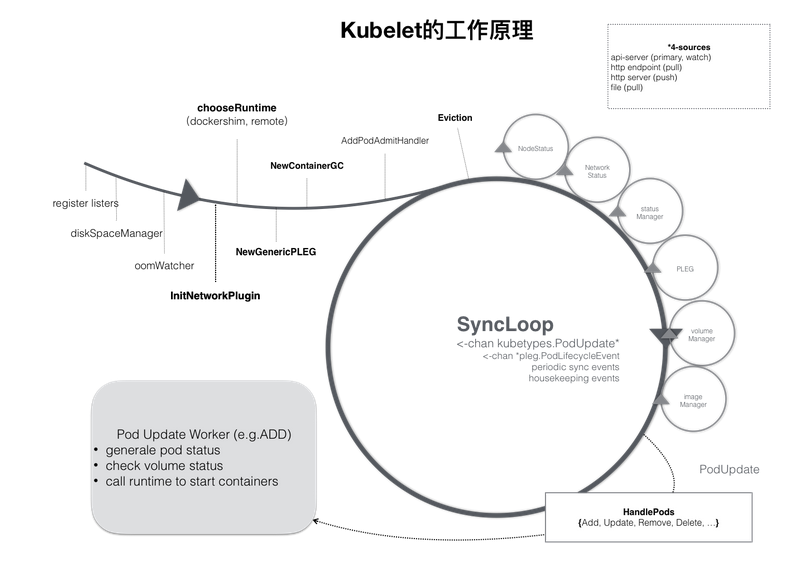
可以看到,kubelet 的工作核心,就是一个控制循环,即:SyncLoop。驱动整个控制循环的事件有:pod更新事件、pod生命周期变化、kubelet本身设置的执行周期、定时清理事件等。在SyncLoop循环上还有很多Manager,例如probeManager 会定时去监控 pod 中容器的健康状况、statusManager 负责维护状态信息,并把 pod 状态更新到 apiserver、ontainerRefManager 容器引用的管理等等。不过这些Manage在这里先不管,只聚焦于Pod的创建。
整个Kubelet的启动,都记录在kubernetes\pkg\kubelet\kubelet.go文件中的Run方法中:
// Run starts the kubelet reacting to config updates
func (kl *Kubelet) Run(updates <-chan kubetypes.PodUpdate) {
//注册 logServer
if kl.logServer == nil {
kl.logServer = http.StripPrefix("/logs/", http.FileServer(http.Dir("/var/log/")))
}
if kl.kubeClient == nil {
glog.Warning("No api server defined - no node status update will be sent.")
}
if err := kl.initializeModules(); err != nil {
kl.recorder.Eventf(kl.nodeRef, v1.EventTypeWarning, events.KubeletSetupFailed, err.Error())
glog.Fatal(err)
}
// Start volume manager
go kl.volumeManager.Run(kl.sourcesReady, wait.NeverStop)
if kl.kubeClient != nil {
// Start syncing node status immediately, this may set up things the runtime needs to run.
go wait.Until(kl.syncNodeStatus, kl.nodeStatusUpdateFrequency, wait.NeverStop)
}
go wait.Until(kl.syncNetworkStatus, 30*time.Second, wait.NeverStop)
go wait.Until(kl.updateRuntimeUp, 5*time.Second, wait.NeverStop)
// Start loop to sync iptables util rules
if kl.makeIPTablesUtilChains {
go wait.Until(kl.syncNetworkUtil, 1*time.Minute, wait.NeverStop)
}
// Start a goroutine responsible for killing pods (that are not properly
// handled by pod workers).
go wait.Until(kl.podKiller, 1*time.Second, wait.NeverStop)
// Start gorouting responsible for checking limits in resolv.conf
if kl.dnsConfigurer.ResolverConfig != "" {
go wait.Until(func() { kl.dnsConfigurer.CheckLimitsForResolvConf() }, 30*time.Second, wait.NeverStop)
}
// Start component sync loops.
kl.statusManager.Start()
kl.probeManager.Start()
// Start the pod lifecycle event generator.
//启动 pleg 该模块主要用于周期性地向 container runtime 刷新当前所有容器的状态
kl.pleg.Start()
kl.syncLoop(updates, kl)
}Run方法以kl.syncLoop方法结尾。实际上,它是通过最后调用kl.syncLoop来启动事件循环,循环的监听管道信息,而我们要的Pod创建代码,就在其中。
// in pkg/kubelet/kubelet.go
func (kl *Kubelet) syncLoop(updates <-chan kubetypes.PodUpdate, handler SyncHandler) {
glog.Info("Starting kubelet main sync loop.")
// The resyncTicker wakes up kubelet to checks if there are any pod workers
// that need to be sync'd. A one-second period is sufficient because the
// sync interval is defaulted to 10s.
syncTicker := time.NewTicker(time.Second)
defer syncTicker.Stop()
housekeepingTicker := time.NewTicker(housekeepingPeriod)
defer housekeepingTicker.Stop()
plegCh := kl.pleg.Watch()
for {
if rs := kl.runtimeState.runtimeErrors(); len(rs) != 0 {
glog.Infof("skipping pod synchronization - %v", rs)
time.Sleep(5 * time.Second)
continue
}
kl.syncLoopMonitor.Store(kl.clock.Now())
if !kl.syncLoopIteration(updates, handler, syncTicker.C, housekeepingTicker.C, plegCh) {
break
}
kl.syncLoopMonitor.Store(kl.clock.Now())
}
}该方法的主要逻辑在kl.syncLoopIteration中实现,点进去,查看和Pod增删改有关的核心代码:
// in pkg/kubelet/kubelet.go
func (kl *Kubelet) syncLoopIteration(configCh <-chan kubetypes.PodUpdate, handler SyncHandler,
syncCh <-chan time.Time, housekeepingCh <-chan time.Time, plegCh <-chan *pleg.PodLifecycleEvent) bool {
select {
case u, open := <-configCh:
// Update from a config source; dispatch it to the right handler
// callback.
if !open {
glog.Errorf("Update channel is closed. Exiting the sync loop.")
return false
}
switch u.Op {
case kubetypes.ADD:
glog.V(2).Infof("SyncLoop (ADD, %q): %q", u.Source, format.Pods(u.Pods))
// After restarting, kubelet will get all existing pods through
// ADD as if they are new pods. These pods will then go through the
// admission process and *may* be rejected. This can be resolved
// once we have checkpointing.
handler.HandlePodAdditions(u.Pods)
case kubetypes.UPDATE:
glog.V(2).Infof("SyncLoop (UPDATE, %q): %q", u.Source, format.PodsWithDeletiontimestamps(u.Pods))
handler.HandlePodUpdates(u.Pods)
case kubetypes.REMOVE:
glog.V(2).Infof("SyncLoop (REMOVE, %q): %q", u.Source, format.Pods(u.Pods))
handler.HandlePodRemoves(u.Pods)
case kubetypes.RECONCILE:
glog.V(4).Infof("SyncLoop (RECONCILE, %q): %q", u.Source, format.Pods(u.Pods))
handler.HandlePodReconcile(u.Pods)
case kubetypes.DELETE:
glog.V(2).Infof("SyncLoop (DELETE, %q): %q", u.Source, format.Pods(u.Pods))
// DELETE is treated as a UPDATE because of graceful deletion.
handler.HandlePodUpdates(u.Pods)
case kubetypes.RESTORE:
glog.V(2).Infof("SyncLoop (RESTORE, %q): %q", u.Source, format.Pods(u.Pods))
// These are pods restored from the checkpoint. Treat them as new
// pods.
handler.HandlePodAdditions(u.Pods)
case kubetypes.SET:
// TODO: Do we want to support this?
glog.Errorf("Kubelet does not support snapshot update")
}
......
}该模块将同时监视Pod 信息的变化,一旦某个来源的 Pod 信息发生了更新(创建/更新/删除),这个 channel 中就会出现被更新的 Pod 信息和更新的具体操作。
其中,HandlePodAdditions就是创建Pod的接口,其实现体为:
// in pkg/kubelet/kubelet.go
// HandlePodAdditions is the callback in SyncHandler for pods being added from
// a config source.
func (kl *Kubelet) HandlePodAdditions(pods []*v1.Pod) {
start := kl.clock.Now()
sort.Sort(sliceutils.PodsByCreationTime(pods))
for _, pod := range pods {
existingPods := kl.podManager.GetPods()
// Always add the pod to the pod manager. Kubelet relies on the pod
// manager as the source of truth for the desired state. If a pod does
// not exist in the pod manager, it means that it has been deleted in
// the apiserver and no action (other than cleanup) is required.
kl.podManager.AddPod(pod)
if kubepod.IsMirrorPod(pod) {
kl.handleMirrorPod(pod, start)
continue
}
if !kl.podIsTerminated(pod) {
// Only go through the admission process if the pod is not
// terminated.
// We failed pods that we rejected, so activePods include all admitted
// pods that are alive.
activePods := kl.filterOutTerminatedPods(existingPods)
// Check if we can admit the pod; if not, reject it.
if ok, reason, message := kl.canAdmitPod(activePods, pod); !ok {
kl.rejectPod(pod, reason, message)
continue
}
}
mirrorPod, _ := kl.podManager.GetMirrorPodByPod(pod)
//把 pod 分配给给 worker 做异步处理,创建pod
kl.dispatchWork(pod, kubetypes.SyncPodCreate, mirrorPod, start)
kl.probeManager.AddPod(pod)
}
}其主要任务为:
> 按照创建时间给pods进行排序;
> 将pod添加到pod管理器中,如果有pod不存在在pod管理器中,那么这个pod表示已经被删除了;
> 校验pod 是否能在该节点运行,如果不可以直接拒绝;
> 调用dispatchWork把 pod 分配给给 worker 做异步处理,创建pod;
> 将pod添加到probeManager中,如果 pod 中定义了 readiness 和 liveness 健康检查,启动 > goroutine 定期进行检测;因此,真正创建Pod的其实是方法dispatchWork,其核心代码如下:
// in pkg/kubelet/kubelet.go
// dispatchWork starts the asynchronous sync of the pod in a pod worker.
// If the pod is terminated, dispatchWork
func (kl *Kubelet) dispatchWork(pod *v1.Pod, syncType kubetypes.SyncPodType, mirrorPod *v1.Pod, start time.Time) {
......
// Run the sync in an async worker.
kl.podWorkers.UpdatePod(&UpdatePodOptions{
Pod: pod,
MirrorPod: mirrorPod,
UpdateType: syncType,
OnCompleteFunc: func(err error) {
if err != nil {
metrics.PodWorkerLatency.WithLabelValues(syncType.String()).Observe(metrics.SinceInMicroseconds(start))
}
},
})
......
}也就是说,该方法会封装一个UpdatePodOptions结构体丢给podWorkers.UpdatePod去执行,该文件位于 pkg/kubelet/pod_workers.go 中。我们点进去看看:
// Apply the new setting to the specified pod.
// If the options provide an OnCompleteFunc, the function is invoked if the update is accepted.
// Update requests are ignored if a kill pod request is pending.
func (p *podWorkers) UpdatePod(options *UpdatePodOptions) {
pod := options.Pod
uid := pod.UID
var podUpdates chan UpdatePodOptions
var exists bool
p.podLock.Lock()
defer p.podLock.Unlock()
//如果该pod在podUpdates数组里面不存在,那么就创建channel,并启动异步线程
if podUpdates, exists = p.podUpdates[uid]; !exists {
// We need to have a buffer here, because checkForUpdates() method that
// puts an update into channel is called from the same goroutine where
// the channel is consumed. However, it is guaranteed that in such case
// the channel is empty, so buffer of size 1 is enough.
podUpdates = make(chan UpdatePodOptions, 1)
p.podUpdates[uid] = podUpdates
// Creating a new pod worker either means this is a new pod, or that the
// kubelet just restarted. In either case the kubelet is willing to believe
// the status of the pod for the first pod worker sync. See corresponding
// comment in syncPod.
go func() {
defer runtime.HandleCrash()
p.managePodLoop(podUpdates)
}()
}
if !p.isWorking[pod.UID] {
p.isWorking[pod.UID] = true
podUpdates <- *options
} else {
// if a request to kill a pod is pending, we do not let anything overwrite that request.
update, found := p.lastUndeliveredWorkUpdate[pod.UID]
if !found || update.UpdateType != kubetypes.SyncPodKill {
p.lastUndeliveredWorkUpdate[pod.UID] = *options
}
}
}该方法会加锁之后获取podUpdates数组里面数据,如果不存在那么会创建一个channel然后执行一个异步协程,我们进入managePodLoop来看看:
func (p *podWorkers) managePodLoop(podUpdates <-chan UpdatePodOptions) {
var lastSyncTime time.Time
for update := range podUpdates {
err := func() error {
podUID := update.Pod.UID
// This is a blocking call that would return only if the cache
// has an entry for the pod that is newer than minRuntimeCache
// Time. This ensures the worker doesn't start syncing until
// after the cache is at least newer than the finished time of
// the previous sync.
status, err := p.podCache.GetNewerThan(podUID, lastSyncTime)
if err != nil {
// This is the legacy event thrown by manage pod loop
// all other events are now dispatched from syncPodFn
p.recorder.Eventf(update.Pod, v1.EventTypeWarning, events.FailedSync, "error determining status: %v", err)
return err
}
err = p.syncPodFn(syncPodOptions{
mirrorPod: update.MirrorPod,
pod: update.Pod,
podStatus: status,
killPodOptions: update.KillPodOptions,
updateType: update.UpdateType,
})
lastSyncTime = time.Now()
return err
}()
// notify the call-back function if the operation succeeded or not
if update.OnCompleteFunc != nil {
update.OnCompleteFunc(err)
}
if err != nil {
// IMPORTANT: we do not log errors here, the syncPodFn is responsible for logging errors
glog.Errorf("Error syncing pod %s (%q), skipping: %v", update.Pod.UID, format.Pod(update.Pod), err)
}
p.wrapUp(update.Pod.UID, err)
}
}该方法会遍历channel里面的数据,然后调用syncPodFn方法并传入一个syncPodOptions。syncPodFn是啥?实际上,kubelet会在执行NewMainKubelet方法时调用newPodWorkers方法,将syncPodFn设置为 pkg/kubelet/kubelet.go 下的syncPod方法。
func NewMainKubelet(...){
...
klet := &Kubelet{...}
...
klet.podWorkers = newPodWorkers(klet.syncPod, kubeDeps.Recorder, klet.workQueue, klet.resyncInterval, backOffPeriod, klet.podCache)
...
}接下来,我们的重点,来到了syncPod中。该方法进行的工作很多很多,不过我都不知道…,以后在学吧。在该方法的注释中,这样解释到:
// The workflow is:
// * If the pod is being created, record pod worker start latency
// * Call generateAPIPodStatus to prepare an v1.PodStatus for the pod
// * If the pod is being seen as running for the first time, record pod
// start latency
// * Update the status of the pod in the status manager
// * Kill the pod if it should not be running
// * Create a mirror pod if the pod is a static pod, and does not
// already have a mirror pod
// * Create the data directories for the pod if they do not exist
// * Wait for volumes to attach/mount
// * Fetch the pull secrets for the pod
// * Call the container runtime’s SyncPod callback
// * Update the traffic shaping for the pod’s ingress and egress limits
//
// If any step of this workflow errors, the error is returned, and is repeated
// on the next syncPod call.
这些东西我们先不管,现在只需要知道,该方法会完成Pod基础目录创建(包括和volume有关的)以及对volume的挂载。也就是说,和本漏洞有关的代码,从这里开始!
Volume挂载过程
在一个Pod开始运行前,k8s需要做许多事情。首先,Kubelet为Pod在宿主机上创建了一个基础目录:
func (kl *Kubelet) syncPod(o syncPodOptions) error {
......
// Make data directories for the pod
if err := kl.makePodDataDirs(pod); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedToMakePodDataDirectories, "error making pod data directories: %v", err)
glog.Errorf("Unable to make pod data directories for pod %q: %v", format.Pod(pod), err)
return err
}
......
}可以看到,syncPod通过调用makePodDataDirs方法来为Pod创建基础目录,我们跟进看看:
// makePodDataDirs creates the dirs for the pod datas.
func (kl *Kubelet) makePodDataDirs(pod *v1.Pod) error {
uid := pod.UID
if err := os.MkdirAll(kl.getPodDir(uid), 0750); err != nil && !os.IsExist(err) {
return err
}
if err := os.MkdirAll(kl.getPodVolumesDir(uid), 0750); err != nil && !os.IsExist(err) {
return err
}
if err := os.MkdirAll(kl.getPodPluginsDir(uid), 0750); err != nil && !os.IsExist(err) {
return err
}
return nil
}该方法一共调用了三次MkdirAll方法,其中第二次调用,就是关于volume目录的。接着,我们回到synPod,观察下一个方法调用:
// Volume manager will not mount volumes for terminated pods
if !kl.podIsTerminated(pod) {
// Wait for volumes to attach/mount
if err := kl.volumeManager.WaitForAttachAndMount(pod); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedMountVolume, "Unable to mount volumes for pod %q: %v", format.Pod(pod), err)
glog.Errorf("Unable to mount volumes for pod %q: %v; skipping pod", format.Pod(pod), err)
return err
}
}也就是说,Kubelet在为Pod创建完基础目录后,会等待Kubelet Volume Manager(pkg/kubelet/volumemanager)将Pod声明文件中声明的卷挂载到上述Volumes目录下。
完成上述操作后,再回到syncPod中,它会调用containerRuntime.SyncPod,来真正的创建Pod。
// Call the container runtime's SyncPod callback
result := kl.containerRuntime.SyncPod(pod, apiPodStatus, podStatus, pullSecrets, kl.backOff)该文件位于 pkg/kubelet/kuberuntime/kuberuntime_manager.go。直接看该代码的第5步的核心部分:
func (m *kubeGenericRuntimeManager) SyncPod(...) {
......
// Step 5: start the init container.
...
if msg, err := m.startContainer(podSandboxID, podSandboxConfig, container, pod, podStatus, pullSecrets, podIP); err != nil {
startContainerResult.Fail(err, msg)
utilruntime.HandleError(fmt.Errorf("init container start failed: %v: %s", err, msg))
return
}
......
}进入startContainer,发现其会调用m.generateContainerConfig来为容器运行时(Runtime)生成配置文件:
containerConfig, err := m.generateContainerConfig(container, pod, restartCount, podIP, imageRef)从generateContainerConfig一直往下追溯,直到位于 pkg/kubelet/kubelet_pods.go 中的GenerateRunContainerOptions方法。该方法会调用makeMounts来生成容器运行时的挂载映射表:
// in pkg/kubelet/kubelet_pods.go GenerateRunContainerOptions function
mounts, err := makeMounts(pod, kl.getPodDir(pod.UID), container, hostname, hostDomainName, podIP, volumes)而makeMounts,就是漏洞的关键所在。
漏洞分析
先进makdMounts里看下:
// in pkg/kubelet/kubelet_pods.go
// makeMounts determines the mount points for the given container.
func makeMounts(pod *v1.Pod, podDir string, container *v1.Container, hostName, hostDomain, podIP string, podVolumes kubecontainer.VolumeMap) ([]kubecontainer.Mount, error) {
// ...
mounts := []kubecontainer.Mount{}
for _, mount := range container.VolumeMounts {
// ...
hostPath, err := volume.GetPath(vol.Mounter)
if err != nil {
return nil, err
}
if mount.SubPath != "" {
if filepath.IsAbs(mount.SubPath) {
return nil, fmt.Errorf("error SubPath `%s` must not be an absolute path", mount.SubPath)
}
err = volumevalidation.ValidatePathNoBacksteps(mount.SubPath)
if err != nil {
return nil, fmt.Errorf("unable to provision SubPath `%s`: %v", mount.SubPath, err)
}
fileinfo, err := os.Lstat(hostPath)
if err != nil {
return nil, err
}
perm := fileinfo.Mode()
// 关键点1
hostPath = filepath.Join(hostPath, mount.SubPath)
if subPathExists, err := utilfile.FileOrSymlinkExists(hostPath); err != nil {
glog.Errorf("Could not determine if subPath %s exists; will not attempt to change its permissions", hostPath)
} else if !subPathExists {
// Create the sub path now because if it's auto-created later when referenced, it may have an
// incorrect ownership and mode. For example, the sub path directory must have at least g+rwx
// when the pod specifies an fsGroup, and if the directory is not created here, Docker will
// later auto-create it with the incorrect mode 0750
if err := os.MkdirAll(hostPath, perm); err != nil {
glog.Errorf("failed to mkdir:%s", hostPath)
return nil, err
}
// chmod the sub path because umask may have prevented us from making the sub path with the same
// permissions as the mounter path
if err := os.Chmod(hostPath, perm); err != nil {
return nil, err
}
}
}
// ...
// 关键点2
mounts = append(mounts, kubecontainer.Mount{
Name: mount.Name,
ContainerPath: containerPath,
HostPath: hostPath,
ReadOnly: mount.ReadOnly,
SELinuxRelabel: relabelVolume,
Propagation: propagation,
})
}
// ...
return mounts, nil
}可以看到,该方法体中就出现了subPath这个东西。现在来分析下,在生成挂载映射表时,它是怎么处理hostPath和subPath的。假设subPath不为空。
首先,检验subPath是否为绝对路径,如果是则err,因为子路径不能为绝对路径。然后,检验subPath中是否有..这个东西,也即是否有调用上级目录的行为,如果有,则err。后者的存在至关重要,正因为该检查,使Pod无法通过合法挂载目录/../的方法来进行逃逸。
然后就没了。它仅仅对subPath做了上述两步检查,随后就直接和hostPath进行拼接,得到subPath的绝对路径,并检验是否已存在。没错,仅仅就这两步。合并完成后,Kubelet将该绝对路径加入到挂载映射表(mounts变量)中,最终,该表被交给Runtime来创建容器。
在一般的Pod安全策略中,会限制Pod只能挂载指定目录的卷,假设为/tmp/。但是,它并不会现在Pod在该卷下的subPath,并且通过上述源码分析可知源码内部也没有进行什么限制。
问题来了,攻击者可以通过将subPath设成软连接的方式,在合法的hostPaht中逃逸到任何想去的宿主机目录中。
比如,攻击者首先创建一个Pod1,将容器内目录/vuln合法的挂载到/tmp/test下,现在,他在卷中创建一个软连接,使其指向宿主机的根目录/,命令很简单:
kubectl exec -it stage-1-container -- ln -s / /vuln/xxx这样一来,在宿主机的/tmp/test下就多出了指向/的软连接xxx。接下来,攻击者又创建了Pod2,并将subPath设为xxx。基于前面的分析,Kubelet会直接在宿主机上生成指向hostPath+subPath的路径传递给Runtime,致使Pod2的挂载目录直接跳到了宿主机的/处,实现逃逸!



