SSTable(Sorted String Table)是一个简单,但是非常有用的用来交换大量的、排好序的数据片段的数据结构。其使用场景为:
- 需要高效地存储大量地 K-V 数据;
- 数据是顺序写入的;
- 要求高效地顺序读写;
- 没有随机读取或者对随机读取性能要求不高;
BigTable 论文中对 SSTable 这样介绍:
SSTable 提供一个可持久化,有序的、不可变的从键到值的映射关系,其中键和值都是任意字节长度的字符串。SSTable 提供了以下操作:
按照某个键来查询关联值,可以指定键的范围,来遍历其中所有的键值对。每个 SSTable 内部由一系列块((block)组成(通常每块大小为64KB,是可配置的)。使用存储在 SSTable 结尾的块索引(block index)来定位块;当 SSTable 打开时,索引会被加载到内存里。一次磁盘寻道(disk seek)就可以完成查询(lookup)操作:首先通过二分查找在存储在内存的索引中找到对应的块,然后从磁盘上读取这块内容。SSTable 也可以完整地映射到内存里,这样在执行查询和扫描(scan)的时候就不用操作磁盘了.
简单来讲,SSTable 是一个键是有序的,存储字符串形式键值对的文件。每个 SSTable 包含一系列的数据块(Data Block,以下简称 Block),在 SSTable 的末尾是索引块,用于定位 Block。其结构简单来看,如下图所示:

从上图可以看到,因为 SSTable 文件中所有的键值对 <key,value> 是存放到一起的,所以 SSTable 在序列化成文件之后,是不可变的,因为此时的 SSTable,就类似于一个数组一样,如果插入或者删除,需要移动一大片数据,开销很大。
然而实际上,BigTable 中的 SSTable 结构比上面那张图复杂的多,它长这样:
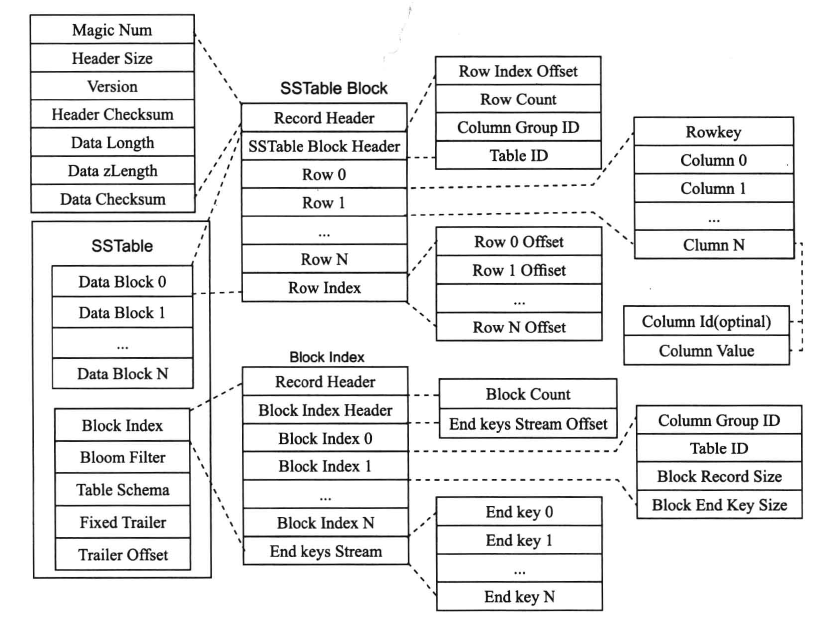
SSTable 中的数据按 key 排序后存放在连续的数据块(Block) 中,Block 之间也有序。在众多 Block 之后,为索引块,其中存着每一个 Block 的索引,由每个 Block 最后一行的 key 组成,由用于数据查询中定位 Block。接着,存放布隆过滤器和表格的 Schema 信息。最后,存放固定大小的 Trailer 以及 Trailer的 Offset。
- Data Block:存放连续的数据块。
- Block Index:存放连续的块索引。描述一个 Block,存储着对应 Block 的最大 Key 值,以及 Block 在文件中的偏移量和大小。
- Bloom Filter:布隆过滤器(Bloom Filter),用于判断读取的数据是否在当前 SSTable 上。
- Table Schema: 当前 SSTable 的表格Schema信息。
- Fixed Trailer:当前 SSTable 的Block Index的块索引大小。
- Trailer Offset:当前 SSTable 的Block Index的块索引在文件存储下的偏移量。
在 SSTable 中查找 k-v 时,首先从子表的索引信息中读取 SSTable Trailer 的偏移位置,接着获取 Trailer 信息。根据 Trailer 中记录的信息,可以获取块索引的大小和偏移,从而将整个块索引加载到内存中。之后,根据块索引记录的每个 Block 的最后一行的 key,可以通过二分查找定位到查找的 Block,然后将 Block 加载到内存中。加载完 Block 之后,在 Block 内部的行索引(raw index)中进行二分查找,找到相关行的偏移,然后查找到具体某一行Row X,即是我们要找的数据。
本质上看,SSTable 是一个两级索引结构:块索引以及行索引。
具体的 SSTable 是怎么实现的,需要去看 Rocksdb 的源码,等理清源码实现之后,我再写一篇博客来记录。



