RocksMash | 本地与云相结合的高效益存储系统
如何利用本地存储与云存储相得益彰的特性,优化 LSM-Tree 云存储的成本与性能?
现如今采用云存储是大势所趋,应用程序爆炸式的增长致使存储的数据量不断扩大,这就要求成本效益成为底层数据库的必要设计目标。现行基于 LSM-Tree 的键值存储系统通常使用单盘的模式,要么采用快速但空间小且昂贵的本地存储(如 SSD),要么采用成本较低但速度较慢的云存储盘(如 AWS gp2),难以做到兼顾成本与性能。下图很明显地描述了本地存储和云存储之间的成本与性能差异。其中,左图为不同存储设备的成本-性能分布,SSD 为实例自带的 SSD ,gp2 和 st1 均是 AWS EBS 云盘,前者为 SSD 后者为 HDD。右图为内存耗尽时 RocksDB 在本地 SSD 和 gp2 上的读写性能。
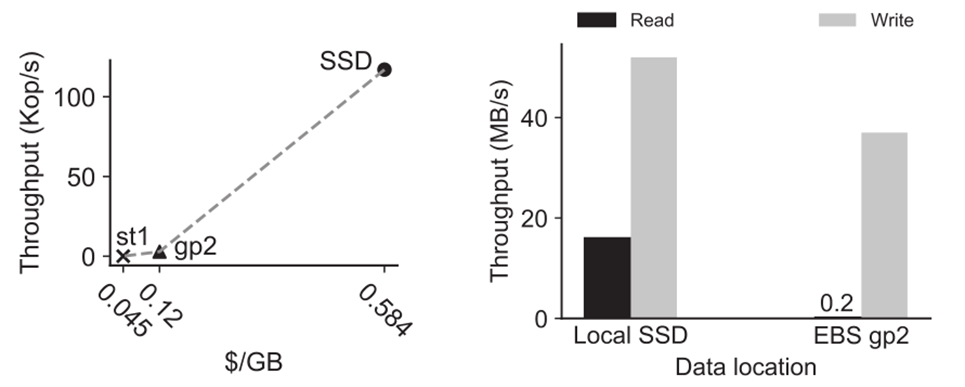
可以看到,两种存储设备具有成本-性能互补的关系,如果能利用这种特性,集成本地存储与云存储,就能打造一个兼具低成本与高性能的存储系统。然而这种双盘分离的设计存在着数据重组、元数据开销与可靠性的问题,目前尚未有其他工作能够在本地存储与云存储之间很好地解决这些问题。
因此,我们设计了 RocksMash。
RocksMash 总览
RocksMash 是基于 RocksDB 设计的一种结合本地存储与云存储的冷热分离存储系统,其重心在于成本的节省、冷区读性能的优化与快速恢复。不同于普通的冷热分离结构,RocksMash 将会在本地盘中对云盘上的元数据进行缓存,降低了对云存储的 I/O 请求数量,优化了读取性能。同时,RocksMash 重新设计了云盘上 SST 的元数据块结构,使元数据体积变小且过滤器的假阳性率降为 0,以此来优化空间利用率和读取性能。此外,RocksMash 使用扩展的 WAL 日志来实现快速的数据并行恢复,保证了可靠性。
与最先进的方案相比,RocksMash 的性能提高了 1.7 倍,且具有高可靠性、高成本效益和快速恢复的特性。
RocksMash 架构
RocksMash 使用小型、快速但通常昂贵的本地存储来存储频繁访问的 LSM-Tree 上层(top-k),而 LSM-Tree 的其余部分则由大型、缓慢但通常便宜的云存储来维护。这是因为上层的大小要远小于下层的大小,SST 的热度也高很多,将顶层放在本地存储中能很好利用其空间小但性能强的特性。上层 SST 存储在本地存储上以实现快速访问,而其余的 SST 存储在云上以实现低存储成。这样可以节省大部分本地存储空间用于缓存,来提高读性能。
为了加速读取存储在云存储上的数据,我们为 RocksMash 设计了 LAP Cache,由 MetaCache 和 DataCache 组成,均使用本地存储,前者负责对 SST 的元数据进行缓存,后者负责完成能够感知 Compaction 的动态数据块缓存。LAP Cache 减少了数据块对云的 I/O,并消除了对云存储中元数据访问。此外,我们为 RocksMash 设计了全新的 SST 元数据结构,称为 MashMeta。MashMeta 显著减少了 SST 元数据的大小,并将假阳性率降为 0。
此外,为了确保本地和云存储混合的数据恢复机制,RocksMash 以几乎可以忽略不计的开销扩展了 WAL(Extended WAL),并将它们存储在专用的、快速的、小型的云存储上,以将本地数据暴露给远程节点。在恢复过程中,提出的扩展 WAL 消除了耗时的上层 Compaction 操作,显著加速了恢复速度。
综上,RocksMash 由如下四部分构成:
冷热分离:上层 SST 由本地存储维护,下层 SST 由云存储维持,平衡性能与成本开销。
LAP Cache:分为 MetaCache 与 DataCache,以有效地使用空闲的本地存储空间作为 SST 元数据和热数据块的高性能持久缓存。
MashMeta:为 SST 设计的一种节省空间的高性能元数据结构,可以显著降低元数据开销,并消除不必要的 I/O 请求。
并行恢复:使用并行的方式快速恢复 L0~Li 的 SST。
下图展示了 RocksMash 的整体架构:
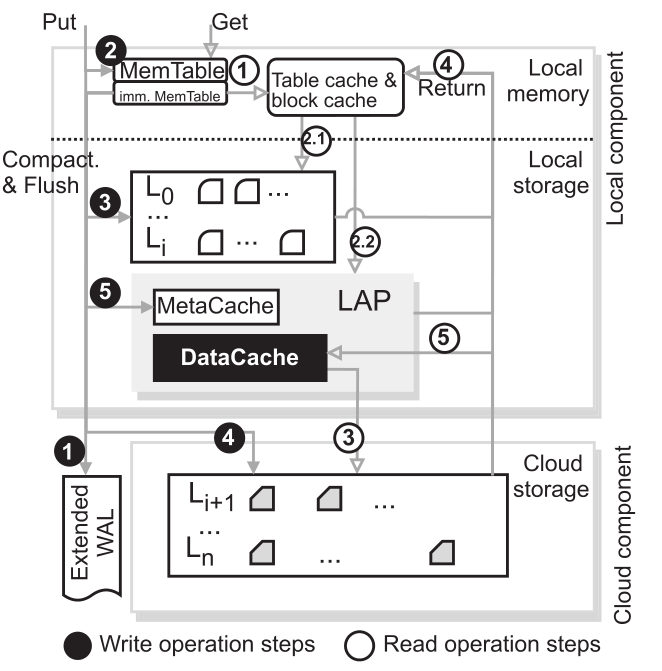
RocksMash 组件设计
接下来将介绍 RocksMash 三大组件的详细设计
LAP Cache
在介绍 LAP Cache 之前,先来看看 RocksDB 的传统 Cache。
RocksDB 的 Cache 通常包含多个 CacheFile,它们被组织在一个 LRU 列表中。新缓存的 k-v 对将被追加进最近使用过的 CacheFile 中,如果该 CacheFile 没满的话。一旦某个 CacheFile 写满了,它会立刻变成只读,此时一个新的 CacheFile 将会被创建并加入到 LRU 列表中。当整个 Cache 满时,最久未被访问的 CacheFile 将会被删除。
这种 Cache 设计是无法感知 Compaction 的,这会浪费大量的缓存空间。比如,在 Cache 中的 k1-v1 原本位于 LSM-Tree 中的 SST1 中,当 SST1 被 Compact 之后,k1-v1 已经过时了,可其仍然存在于 Cache 中,占用了很多空间。
为了解决这个问题,我们提出了 LAP Cache,其由 MetaCache 和 DataCache 两部分组成。
MetaCache
MetaCache 将云存储中所有 SST 的所有元数据块缓存在本地存储中,以此来消除对云端元数据的访问。元数据的总大小对于通常上百 GiB 的本地存储而言很小,因此不会占用过多的空间。由于 SST 自创建后仅仅可读,MetaCache 将云端 SST 的所有元数据块组织在一个 Hash 表中,如下图所示。

为了减少空间占用,RocksMash 重新设计了 SST 的元数据块结构,这将在 MashMeta 部分详细介绍。
使用 MetaCache,RocksMash 可以防止元数据块从本地存储中驱逐出去,这使得 RocksMash 在最坏的情况下只需要一个对本地存储的 I/O 即可访问到云端的 SST 元数据。
DataCache
不同于 RocksDB 的 Cache,DataCache 可以感知到 Compaction 操作。下图描述了其设计方案:
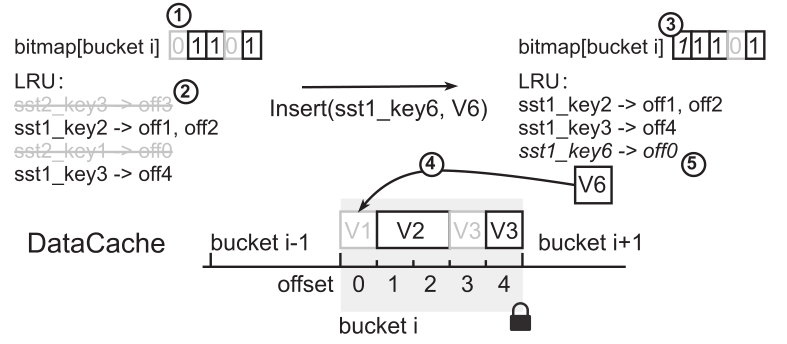
DataCache 将缓存的 k-v 对组织在 LRU 列表中,并把其中位于过时 SST 中的 k-v 对在 bitmap 中进行标记。如上图,当 SST2 被 Compact 时,DataCache 中的 sst2_key3 和 sst2_key1 均会在 bitmap 中被标记,而当新的 k-v 对需要缓存时(sst1_key2 和 sst1_key3),将会把被标记的 k-v 对覆盖掉,以此来提高缓存的空间利用率。
DataCache 被划分为多个 bucket,每个 bucket 维护来自不同 SST 的多个数据块,通过对数据块所在的 SST 的文件名进行 Hash 来决定其会被分配入哪个 bucket。每一个 bucket 均配备有一个 bitmap,其中的每一个 bit 均唯一对应 bucket 中某个数据块。如果 bit 被置位,即说明该数据块包含的是一个有效的 k-v 对。
使用 DataCache,过时的 SST 数据块通过 bitmap 来删除,这样并不会影响有效数据,提高了空间利用率。
MashMeta
为了进一步优化 MetaCache,RocksMash 重构了云存储中的 SST 结构,基于 Succinct-Tree 设计了一种空间高效的索引方法。这种结构将大大减少元数据块的大小,为 SST 节省出更多的空间来存放数据块,从而提高 Cache 的命中率。同时, 该结构支持快速查询,将更快的把 key 从元数据快定位到数据块中。
对云存储中的每一个 SST,RocksMash 构建了一个compressed trie,并将其进行编码,然后用它替代了 SST 中的索引与布隆过滤器。下图展示了一个 10 节点的 trie 示例:
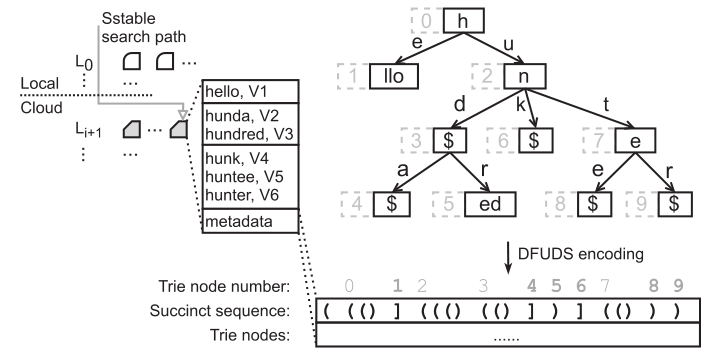
该 SST 一共存放了 6 条 k-v,key 分别为 “hello”、“hunda”、“hundred”、“hunk”、“huntee”、“hunter”,这些 k-v 存放在三个数据块之中。trie 中的每一个节点都关联一个字符和编号,比如根节点就是 “h” 和 0,其中,节点的编号是其在深度优先遍历中的访问顺序,“$“ 代表空。每一条边也关联着一个字符,比如根节点的两条出边关联 “e” 和 “u”。每一条由根节点到叶子节点的路径均代表一个 key,每一个叶子节点代表一个 key 的结尾。
trie 以 DFUDS 进行编码。在深度优先遍历时,每当访问到一个节点,i 个左括号 “(“ 就会被加入序列,其中 i 指该节点的孩子数目。当节点访问完毕后,一个右括号 “)” 会被加入序列。以上图为例,节点 0 访问完毕后会加入字符串 “( ( )”,节点 2 访问完毕后会加入字符串 “( ( ( )”。当所有节点访问完毕后,会形成一个具有 10 对括号的序列,其中,最左侧的 “(“ 是为了平衡括号额外加进去的。在该序列中,从开始到每一个叶子节点的 “)” 或 “]”,即为所对应 key 的编码。
因为 SST 中的 key 是有序的,因此只要知道每一个数据块的起始 key 即可快速定位到 key 所在的数据块。为了做到快速定位,MashMeta 将每个数据块的起始 key 进行了特殊编码。对于每一个起始 key,MashMeta 将其编码中的结尾 “)” 替换成了 “]”。比如 “hello” 的编码结尾本来是 “)”,现在被替换为了 “]”,这就是为什么在上图中节点 2 对应的编码是 “]”。因此,在序列中搜索 key 时,经过的 “]” 数量就代表其位于第几个数据块。比如,在 key “huntee” 的检索过程中遇到了 3 个 “]”,那么其就在第 3 个数据块中。
很显然,这种结构可以完全替代布隆过滤器,并做到 0 假阳性率。因为不存在的 key 是不会在 trie 中有着正确的访问路径的。
并行恢复
实际上,云存储具有较低的年化故障率,因此快速恢复针对于本地存储。
对于常规的 RocksDB WAL。当 WAL 大小较大且覆盖了 L0 ~ Li 的 k-v 对时,其在 CPU 和 I/O 方面均很低效。首先,恢复时没有必要重新构建 Memtable,因为该操作仅仅能生产 L0,而其余层均不可以,这样浪费了 CPU 周期。其次,突然恢复的大量 k-v 必将产生很多 L0~Li 的 Compaction,导致大量的额外 I/O。此外,恢复时的 Compaction 并不是并行的,这进一步拉低了恢复性能。
RocksMash 设计了 L0~Li 的并行恢复方案,以解决上述大尺寸 WAL 带来的问题。
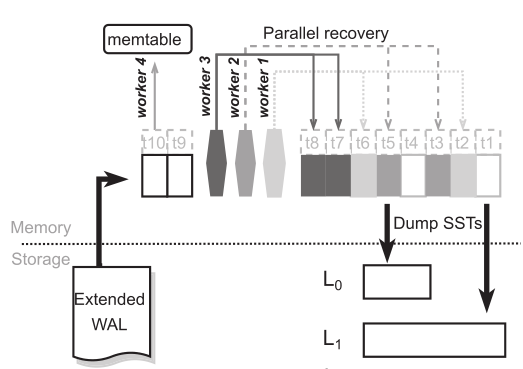
Extended WAL
RocksMash 扩展了 WAL 使其包含 L0Li 中 SST 的所有数据。当 L0Li 中的 SST 生成时,RocksMash 会将该操作记录进 MANIFEST 中,同时将其中的所有 key 记录在 WAL 中,以此来快速确定 SST 中所含的 key。为了节省 I/O,恢复时 RoctksMash 可以将 SST 中的所有 k-v 打包成 batch 进行批量写。Compaction 时要被删除的 SST 中的 key 并不会被 Extended WAL 记录,因为这些 SST 都不在 MANIFEST 所记录的最新状态中。通过这种方式,RocksMash 可以确保安全的回滚到最新的状态。
逆时序搜索
每个需要被恢复的 SST 都会被 RocksMash 分配一个 worker,每个 worker 将会从新至旧搜索 WAL,以确保最先碰到的都是每个 k-v 的最新版本。对于非 L0 的 Li,RocksMash 允许 worker 恢复其中任意版本的 k-v,而非只能是最新的。实际上,Li(i != 0)层中过时版本的 k-v,并不会之后读结果的正确性。假设在 Lx(x != 0)中某一个 SST 中恢复了一条过时的 k-v,不妨称作 k-v_old。可肯定的是在 Lx 中 k-v_old 是该 key 唯一的一条记录,因为除 L0 之外 key 不重合。此外,在 L0~Lx-1 层中一定有比 k-v_old 更新的版本,不放称作 k-v_new,这是因为新版的 k-v 一定会在旧版的 k-v 上层。这样的话,在 LSM-Tree 中进行读取时,就会止步于 k-v_new,而读不到 k-v_old。这种特性与逆时序搜索相结合,将使 RocksMash 从逻辑上截断 WAL。
并行构建 SST
当实例节点故障时,RockMash 将使用一个新的示例去恢复原节点 L0~Li 上的 SST。通过读取 MANIFEST 和 Extended WAL 来获得最新状态的 SST 列表。接着,通过记录的每个 SST 的 key 列表,RockMash 从 Extended WAL 中获得每个 SST 中的 k-v 对,随后并行地重建这些 SST。下图展示了该恢复流程:
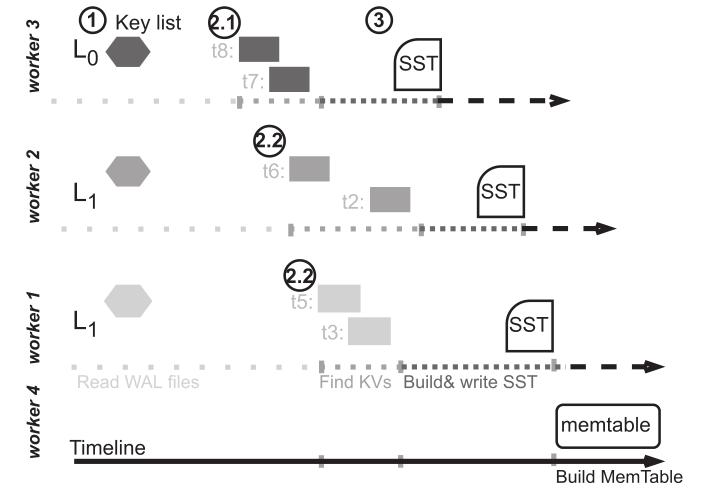
- Step 1:RocksMash 将 L0~Li 中所有 SST 的 key 列表以及所有的 WAL 拉取到新实例中。
- Step 2:为每一个 SST 分配一个 worker,由新至旧扫描 WAL 以此获取到该 SST 应有的 k-v 对。需要注意的是,由于 L0 各 SST 之间是可能重叠的,因此 L0 中较老的 SST 的扫描指针一定不能超过较新的 SST 的扫描指针,以此来保证 L0 中较新的 SST 中一定是较新的 k-v。在 L0 的所有 worker 完成之后,L1~Li 的所有 worker 即开始工作,从 WAL 中拉取 k-v。
- Step 3:当 worker 获取了该 SST 中的所有 k-v 对后,该 SST 将会被重建。
- Step 4:创建 Memtable。RocksMash 通过 L0 中最新的 SST 来判断 WAL 中的 k-v 是否已经持久化,以此来减少写入 Memtable 的大小。L0 中最新的 SST 中最新的 key 可以用作分界线,在该 key 之前的所有 key 都已经被持久化到 SST 中,而该 key 之后的所有 key 还留存在原示例的 Memtable 或 immutable Memtable 中。因此,RocksMash 仅仅将该 key 之后的 key 重放入 Memtable,来恢复内存中的数据。
在以上步骤之后,RocksMash 将崩溃实例的内存和本地存储中的数据恢复到最新的一致状态。
RocksMash 性能评估
该部分分为两节:
- RocksMash 整体性能评估。
- RocksMash 组件性能评估。
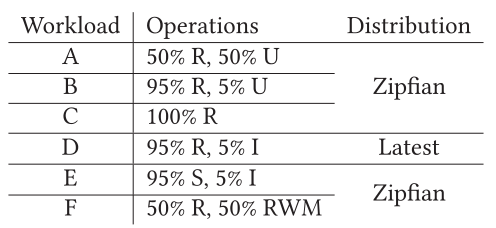
采用 YCSB 的 6 个负载和 db_bench 进行压测,对比 RocksMash、RocksDB、Mutant 三者的性能差异。其中,db_bench 集成了六种模式:随机/顺序写、随机/顺序读,将其记作 “FR”、“FS”、“RR”、“SR”。而YCSB 的 6 个负载如下图所示:
整体性能
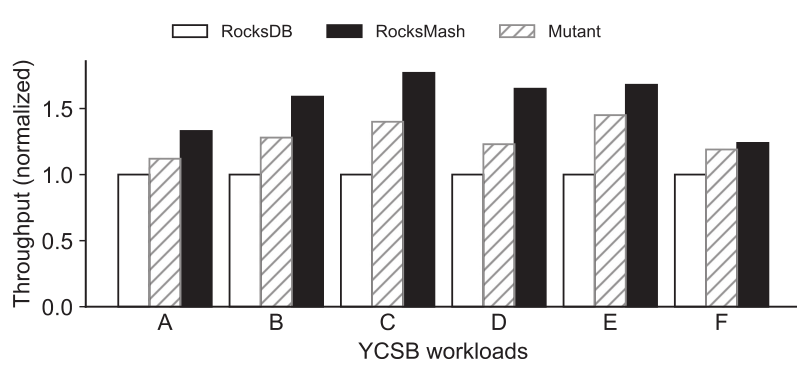
下图显示了在 YCSB 下三种存储系统的 I/O 性能对比。
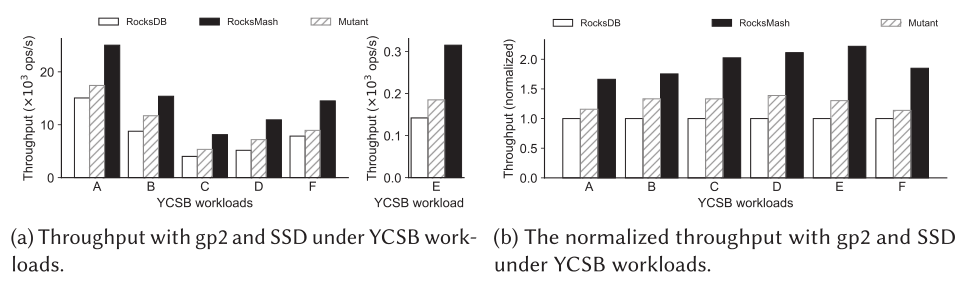
可以看到,RocksMash 在所有六种工作负载下都实现了最高吞吐量。例如,在工作负载 C 下,RocksMash的吞吐量比 RocksDB 提高了2倍。这是因为 RocksDB 将所有数据都存储在云存储上,而负载 C 是 100% 读,说明 RocksMash 的读性能要远优于 RocksDB。而与 Mutant 相比,RocksMash在负载 F 下的吞吐量提高了 1.6 倍,因为 Mutant 采用的 Cache 性能要劣与 RocksMash 采用的 LAP Cache。
对于负载 E,RocksMash 比 RocksDB 和 Mutant 分别提高了 2.2 倍和 1.7 倍。原因如下。首先,与 RocksDB 相比,RocksMash 将热数据存储在快速的本地存储上,这减少了从云端频繁检索的请求,因此提高了整个系统的性能。其次,虽然 Mutant 在本地存储中缓存热数据,但它向缓存中是进行文件级迁移的,这种方式很重,并且它的缓存空间效率不佳。
接下来测试 RocksMash 在分布式系统中的性能。我们将 RockMash 集成在 TiDB 中,集群一共包含 5 个节点。测试结果显示,在 YCSB 的六种负载下,RocksMash 的性能均优于 RocksDB 和 Mutant。
LAP Cache 性能
因为读请求最能反应 Cache 性能,因此该部分测试选用 YCSB 负载 C。与 RocksDB 的对比结果如下:
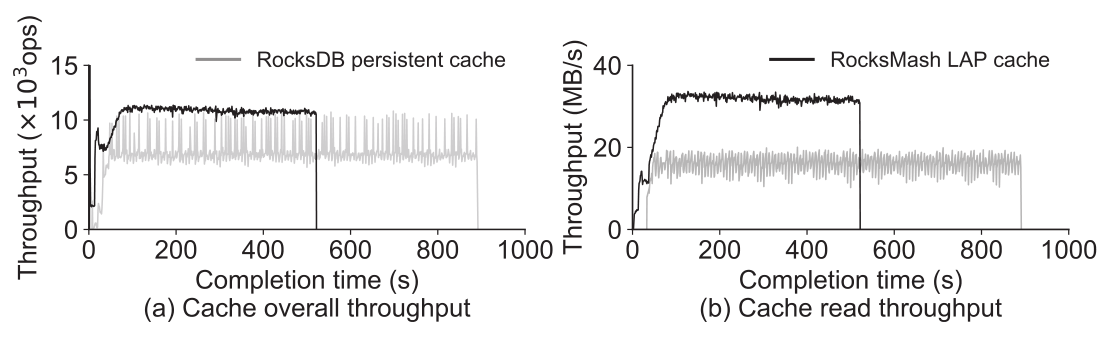
可以看到,LAP Cache 比 RocksDB 的 Cache 拥有更高且更稳定的总体吞吐量。与 RocksDB 相比,RocksMash 的 LAP Cache 由于其高空间效率和高缓存命中率,为用户提供了更高的读吞吐量,将测试完成的时间缩短了一半。
MeshMeta 性能
为了评估 MashMeta 的效果,我们使用只配备了 MashMeta 的 RocksMash 并与 RocksDB 进行比较。在这个测试中,我们将所有数据存储在本地存储中,以缩小元数据结构之间的差异,并加速实验。这里将首先评估 MashMeta 在内存空间上的增益,然后衡量它对读写性能的影响。
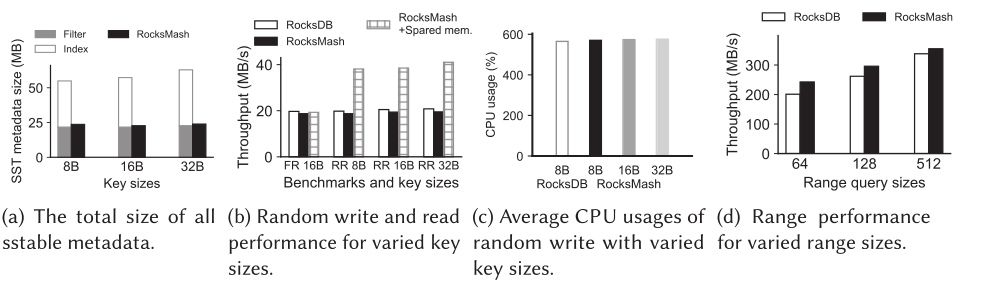
图(a)显示了加载 10M 随机写入后所有 SST 元数据的总大小。与传统的基于块的 SST 元数据相比,MashMeta最多减少 62% 的元数据大小,并将过滤器假阳性率降低到零。
图(b)显示,RocksMash 使用空闲的 32 MB 空间(如图(a)所示)来补偿表和块缓存。因此,在内存耗尽且没有存储空间用于表和块缓存的情况下,随机读性能(图上条形柱)比 RocksMash 和 RocksDB 提高了2倍。
图(c)显示,MashMeta 不会带来显著的开销。这是因为数据传输主导了 Compaction 开销,并且在 Compaction 期间为 SST 构建 MashMeta 只占用了一小部分时间。此外,底层 SST 中 key 之间的长共享前缀有助于减少计算开销。
图(d)显示,RocksMash 提高了所有范围大小的范围查询性能,当范围大小为 64 时,增益最大,达到 1.2 倍。随着范围大小的增长,数据块传输开销占主导地位,MashMeta 的优势逐渐降低。
恢复性能
在本部分将首先评估将 WAL 放在云存储上是否会影响写入性能,然后分析 RocksMash 的并行恢复性能。分别使用本地存储和 AWS EBS-gp3 来存放 WAL。写入吞吐量如下图所示:
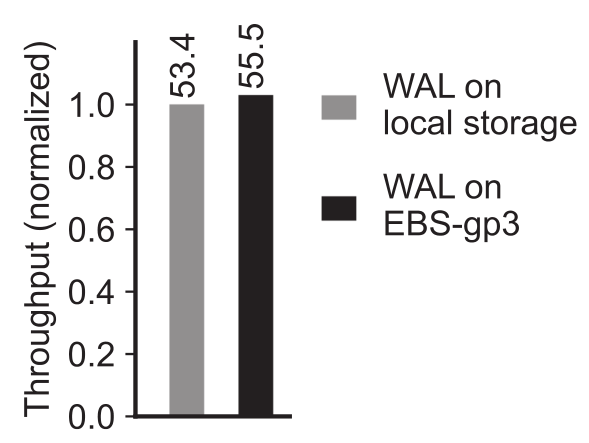
可以看到,在云存储上存放 WAL 对写性能影响很小。
用 db_bench 测试了 RocksMash 并会恢复方案的速度,并于 RocksDB 的恢复方案进行对比,结果如下图:
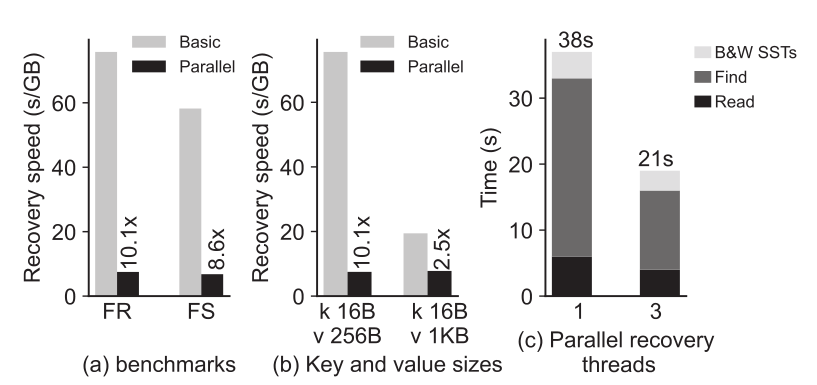
图(a)显示,对于 FR 和 FS 工作负载,RocksMash 的并行恢复方案比基本恢复方案快 8.6 ~ 10.1 倍。
图(b)显示,当 FR 值尺寸较大时,RocksMash 的恢复增益下降到 2.5 倍。
图(c)显示,当 RocksMash 为恢复分配三个线程时,查找属于 SST 的 k-v 对的时间缩短了,而这也是整个恢复过程中最耗时的操作。
结尾
RocksMash 是一个快速高效的基于 LSM-Tree 的存储系统,可以有效地在本地存储和云存储之间分割 LSM-Tree,从而实现成本效益。此外,为了减少元数据的空间占用并提高读取性能,RocksMash 使用了 MetaCache 以节省空间的方式存储元数据,并使用可感知 Compaction 的 DataCache 来缓存有效的数据块。此外,RocksMash 扩展了 WAL,用于快速并行数据恢复。
评估结果表明,与 RocksDB 相比,RocksMash 具有更好的性能、更高的可靠性和成本效益。



