这两天在复现 P2KV 的测试,其中提到了两个概念:user thread 和 background thread。其中,user thread 是客户端的写线程,从下发写请求开始,一直涵盖写 WAL、Memtable 这些前台任务。background thread 更容易理解,就是后台执行 Flush 和 Compact 的线程。
理解了之后,具体该怎么针对的测不同类线程占用的 CPU 呢,这就要改 RocksDB 的源码了。核心思想有两个:
- 获取线程 ID
- 绑核
工具
这里可以借助两个工具: mpstat 和 htop。
其中,mpstat 可以测试某一个 CPU 核的负载,很适合绑核测试方法,htop 则相当于 Linux 下的任务管理器,以线程为单位(严格来说是轻量级进程 lwp) 监控 CPU、Mem 等的占用,很适合第一种测试方法。
mpstat:

htop:
User Thread
采用 db_bench 进行压测,一个 user thread 就是一个写线程,比如下面这条命令就是 8 个 user thread:
./db_bench --benchmarks="fillrandom,stats,levelstats" --threads=8db_bench 有关的源码位于 tools/db_bench_tool.cc下,又 db_bench_tool() 函数为入口,首先完成对参数的初始化核 Benchmark 的创建,然后开始运行 Benchmark。
ROCKSDB_NAMESPACE::Benchmark benchmark;
benchmark.Run();进入 Run() 之后,可以看到它会根据参数选择写入的方式,放入变量 method :
// ...
} else if (name == "fillbatch") {
fresh_db = true;
entries_per_batch_ = 1000;
method = &Benchmark::WriteSeq;
} else if (name == "fillrandom") {
fresh_db = true;
method = &Benchmark::WriteRandom;
}
// ...不管是哪种写模式,都是封装的 DoWrite() ,如下:
void WriteSeq(ThreadState* thread) { DoWrite(thread, SEQUENTIAL); }
void WriteRandom(ThreadState* thread) { DoWrite(thread, RANDOM); }但是多线程的实现不是在这里的。继续 Run() 函数,看到下面这句话:
RunBenchmark(num_threads, name, method);其中,num_threads 就是客户端线程数,在这里是 8。RunBenchmark() 会创建 num_threads 个 ThreaedArg,每个代表一个线程:
Stats RunBenchmark(int n, Slice name,
void (Benchmark::*method)(ThreadState*)) {
// ...
ThreadArg* arg = new ThreadArg[n];
for (int i = 0; i < n; i++) {
arg[i].bm = this;
arg[i].method = method;
arg[i].shared = &shared;
total_thread_count_++;
arg[i].thread = new ThreadState(i, total_thread_count_);
arg[i].thread->stats.SetReporterAgent(reporter_agent.get());
arg[i].thread->shared = &shared;
FLAGS_env->StartThread(ThreadBody, &arg[i]);
}
// ...
}RocksDB 是使用线程池进行线程管理的,而线程池的入口为一个名为 Env 的类。RocksDB 维护了一个 Env 类,这个类在同一个进程中的多个 DB 实例之间是能够共享的,所以 RocksDB 将这个类作为线程池的入口。而 FLAGS_env 就指向 Env 对象。
static ROCKSDB_NAMESPACE::Env* FLAGS_env = ROCKSDB_NAMESPACE::Env::Default();因此,FLAGS_env->StartThread() 就是在线程池创建一个线程,工作内容就是 ThreadBody,因此一个 ThreadBody 就是 user thread。ThreadBody 核心如下:
thread->stats.Start(thread->tid);
(arg->bm->*(arg->method))(thread);
if (FLAGS_perf_level > ROCKSDB_NAMESPACE::PerfLevel::kDisable) {
thread->stats.AddMessage(std::string("PERF_CONTEXT:\n") +
get_perf_context()->ToString());
}
thread->stats.Stop();可以看到,其调用了 method,也就是 DoWrite(),而 DoWrite() 深入下去就是 batch->Put(),之后的流程就是 RocksDB 的写流程了。
因此,想要获取 user thread,只要在 ThreadBody 处打印线程 ID 即可。
static void ThreadBody(void* v) {
// ...
printf("db_bench enters the ThreadBody(), lwpid is: %ld\n", syscall(SYS_gettid));
// ...
}注意,用的是 syscall(SYS_gettid),获取的是 lwp,也就是 htop 种最左边一列的 PID。和 Windows 不同,Linux 严格来讲并没有线程的概念,所谓的 “线程” 都是通过一个名为轻量级进程的东西模拟的,也就是 lwp。参考:LWP与线程
重新编译安装,运行 db_bench,即可看到 8 个 user thread 的 id。
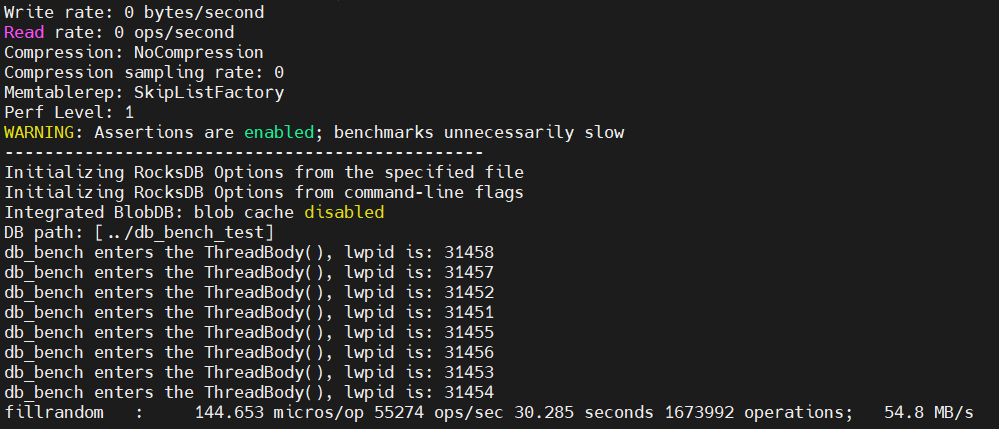
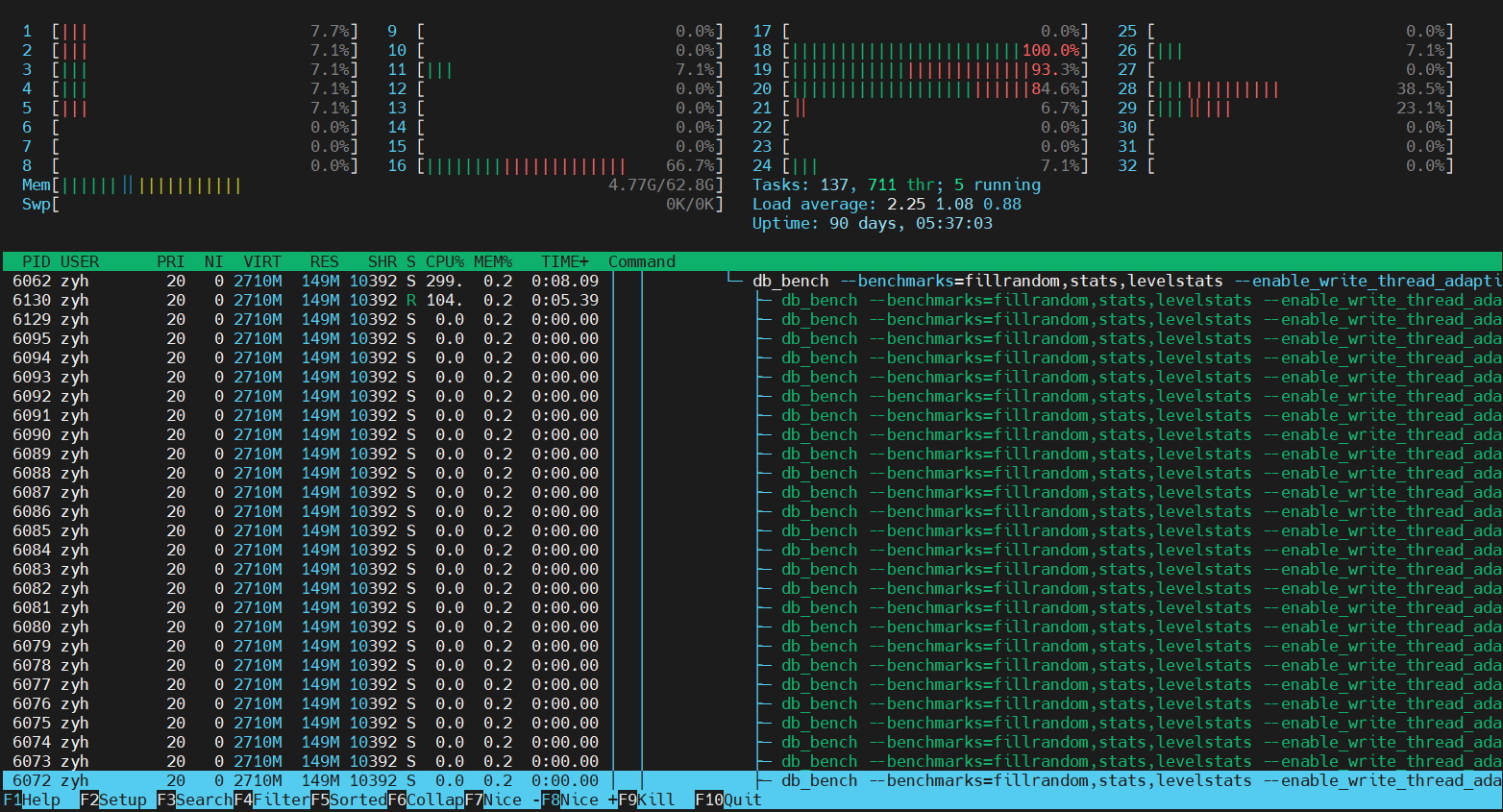
刚好对应 db_bench 在 htop 中的前 8 个线程。
Background Thread
RocksDB 采用的是线程池,Flush / Compaction 任务会交给线程池中的 background thread(BGThread)。在 RocksDB 的线程池中,所有的 BGThread 都是通过 StartBGThreads() 来创建,然后通过 RegisterThread() 来注册进线程池。整个函数调用链如下:
ThreadPoolImpl::Impl::StartBGThreads-->BGThreadWrapper-->ThreadStatusUtil::RegisterThread
StartBGThreads() 函数定义如下:
void ThreadPoolImpl::Impl::StartBGThreads() {
// Start background thread if necessary
while ((int)bgthreads_.size() < total_threads_limit_) {
port::Thread p_t(&BGThreadWrapper,
new BGThreadMetadata(this, bgthreads_.size()));
// Set the thread name to aid debugging
#if defined(_GNU_SOURCE) && defined(__GLIBC_PREREQ)
#if __GLIBC_PREREQ(2, 12)
auto th_handle = p_t.native_handle();
std::string thread_priority = Env::PriorityToString(GetThreadPriority());
std::ostringstream thread_name_stream;
thread_name_stream << "rocksdb:";
for (char c : thread_priority) {
thread_name_stream << static_cast<char>(tolower(c));
}
pthread_setname_np(th_handle, thread_name_stream.str().c_str());
#endif
#endif
bgthreads_.push_back(std::move(p_t));
}
}看到该函数逻辑很简单,只要 BGThread 数量不超过 total_threads_limit_,那就创建。因此想要获取 BGThread 的 id,只需要在 BGThreadWrapper 中打印即可。
void ThreadPoolImpl::Impl::BGThreadWrapper(void* arg) {
// ...
printf("RocksDB starts a BGThread, lwpid is: %ld\n", syscall(SYS_gettid));
// ...
}然后重新编译安装。运行 db_bench,可以看到在 RocksDB 刚启动的时候就创建了很多 BGThread 进入线程池备用,而不是等到 Flush / Compaction 任务来的时候在创建。
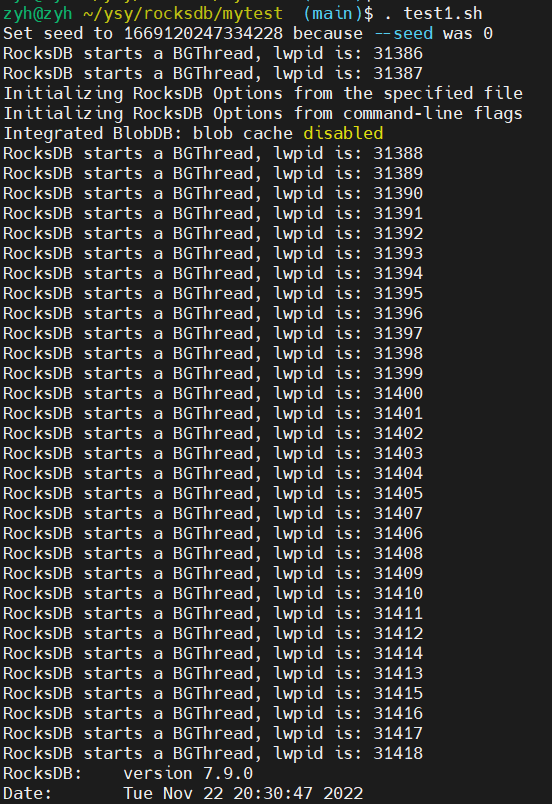
上述 BGThread 一共有 33 个。这个值和 db_bench 中的配置有关,max_background_compactions 决定最多的后台 Compaction 线程数,max_background_flushes 决定最多的后台 Flush 线程数,两者共同组成 BGThread。本此示例中,max_background_compactions = 32,max_background_flushes = 1。
上面的这些 BGThread,刚好对应了 db_bench 在 htop 中除了 8 个 user thread 之外的绝大部分线程(注意,不是全部)。说明客户端的 user thread 和 后台的 background thread 占了 RocksDB 线程池中的绝大部分。
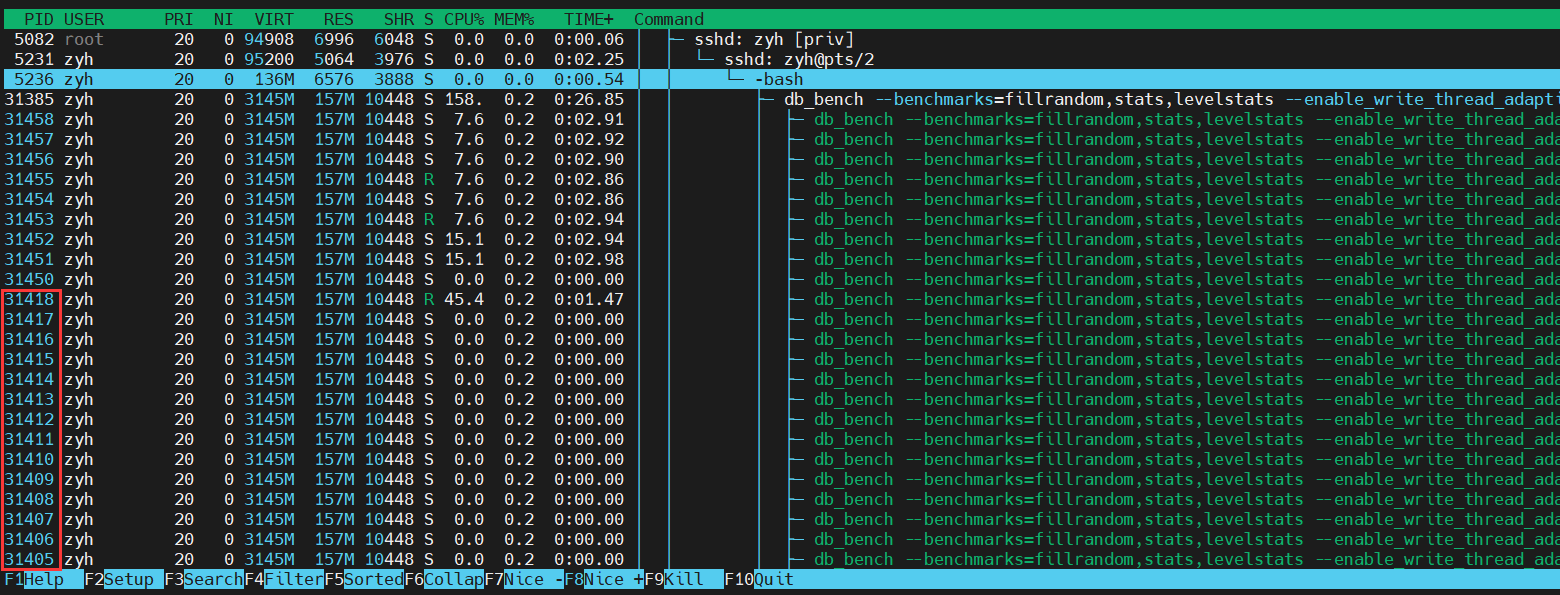
之后,就可以根据 background thread 的 id 去看 background thread 的 CPU、Mem 占用率了。
不过,当 thread 数量过多时,我相测总体的 CPU 占用率,比如我想测 background thread 整体的 CPU 占用率,而不是看某一个 thread,这样的话仅仅依靠 thread id 是很麻烦的,因为不仅要实时监控,还要求和。
因此建议用第二个方法来测:绑核。
绑核
以 background thread 为例,我要测总体的 CPU 利用率,那我就可以在 StartBGThread() 处进行绑核,让所有的 background thread 绑定到一个核上且独占。这样一来,我只需用 mpstat 监控那一个核的 CPU 负载即可。
绑核过程如下:



