本篇针对 EFS 的三种吞吐量模式进行测试,并对结果进行一定的分析与思考。EC2 实例类型采用 m5d.2xlarge,EFS 均为 Standard,由于测试时间短,因此和 IA 无关。关于 EFS 三种模式,官网有大体的介绍:EFS 性能。不过测了之后发现,官网给出的只适合于商业模式下巨量的数据存储,而在实验环境下(数据量少),性能是真的烂。
测试命令
采用 db_bench 进行客户端压测,命令如下:
#!/bin/bash
sudo ../db_bench -benchmarks="fillrandom,levelstats,stats" \
-perf_level=5 \
-compression_type=none \
-histogram=1 \
-statistics \
-num=10000000 \
-threads=X \
-writes=10000000/X \
-max_background_jobs=8 \
-subcompactions=1 \
-max_bytes_for_level_base=$((256*1024*1024)) \
-write_buffer_size=$((8*1024*1024)) \
-writable_file_max_buffer_size=$((16*1024*1024)) \
-target_file_size_base=$((8*1024*1024)) \
-key_size=16 \
-value_size=256 \
-bloom_bits=10 \
-keys_per_prefix=0 \
-cache_index_and_filter_blocks=0 \
-seek_nexts=100 \
-use_direct_io_for_flush_and_compaction=1 \
-use_direct_reads=1 \
--db=/mnt/efs/ysy1/db \
--wal_dir=/mnt/efs/ysy1/wal \
> testX.log突增模式
该模式是 EFS 默认的模式,也是成本相对较低的模式,所以首先测了它,不过结果并不好。
测试分析
该模式下测试了 X = 1、2、4、8 的情况,部分数据如下:

可以看到,不管用户线程数为多少,总的平均 IO 只有 50 MiB/s 左右,和之前 io2 测的 200~300 MiB/s 相比,性能非常差。
在 EFS 控制台中,可以监控到四次压测的实时吞吐量利用率,峰值已经达到 80%+,触发报警,说明已经完全利用了 EFS,达到了吞吐量瓶颈。
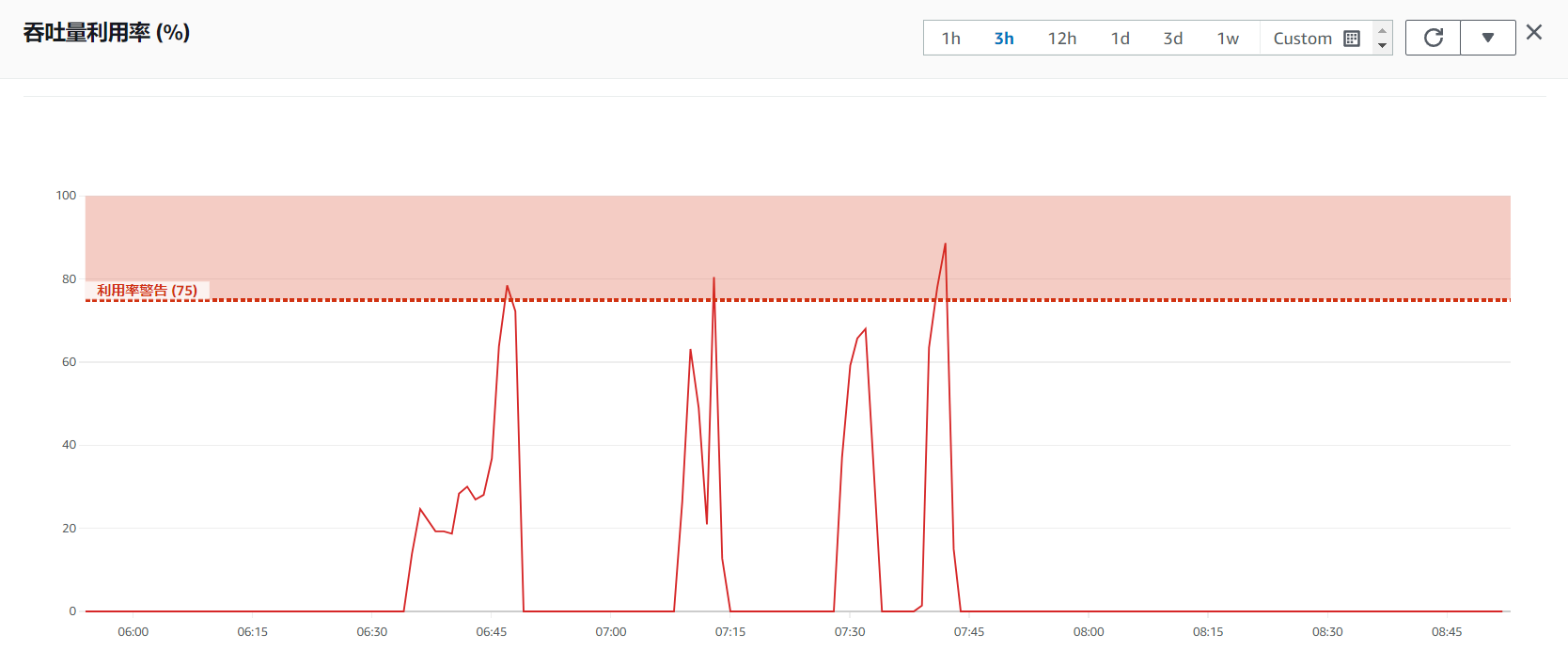
为什么会这样呢?原因在于突发吞吐量模式的吞吐量限制问题。首先,吞吐量利用率指某一刻的吞吐量与允许吞吐量(PermittedThroughput)的比值,该比值不会超过 100%,因为突发吞吐量模式下,PermittedThroughput 就是最大的吞吐量。官方对该限制的描述如下:
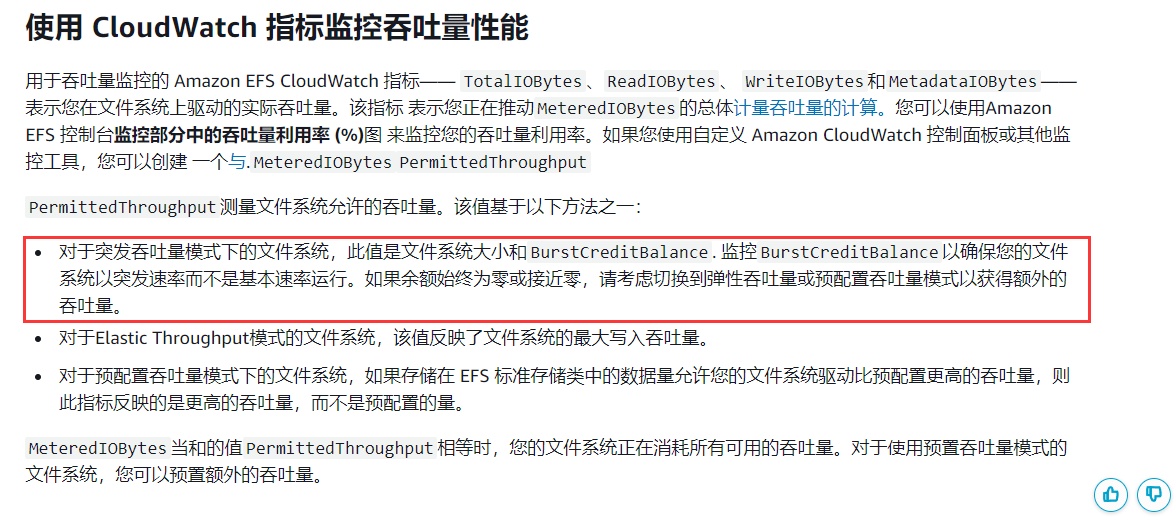
其中,PermittedThroughput 就是允许的最大吞吐量,该值直接由文件系统大小决定。即使使用了突增积分,使吞吐量变大,那这个吞吐量仍然会被限制在这个范围内。
这里说一下突增积分,每当文件系统处于非活动状态或驱动吞吐量低于其基线计量速率时,它就会累积突发积分。但是这个基线基线计量速率极低,与文件系统大小有关,基量为 1MiB/s,每 GiB 提供的基线速率(基线吞吐量)为 50 KB/s,也就是说即使 1 TB 的文件系统也只有 50 MiB/s 的基线速率,对比 io2,少的可怜。因此,在存储大小很低的情况下,稍微来一点压力,就需要用突增积分了 。更何况,我的实验环境为新创建的 EFS,总大小很小,基线速率为最低的 1MiB/s ,因此整个压测过程基本都在用突增积分。
那突增积分是哪来的?除了随着非活动的时间增加而积累,新创建的 EFS 会直接赠送 2.3TB 的突增积分,上述实验用的就是这些积分。在 CloudWatch 中可以监控突增积分的变化,随着四次压测,突增积分降了四次,如下:(最后两次由于压测间隔小于采样间隔,所以没有水平线)
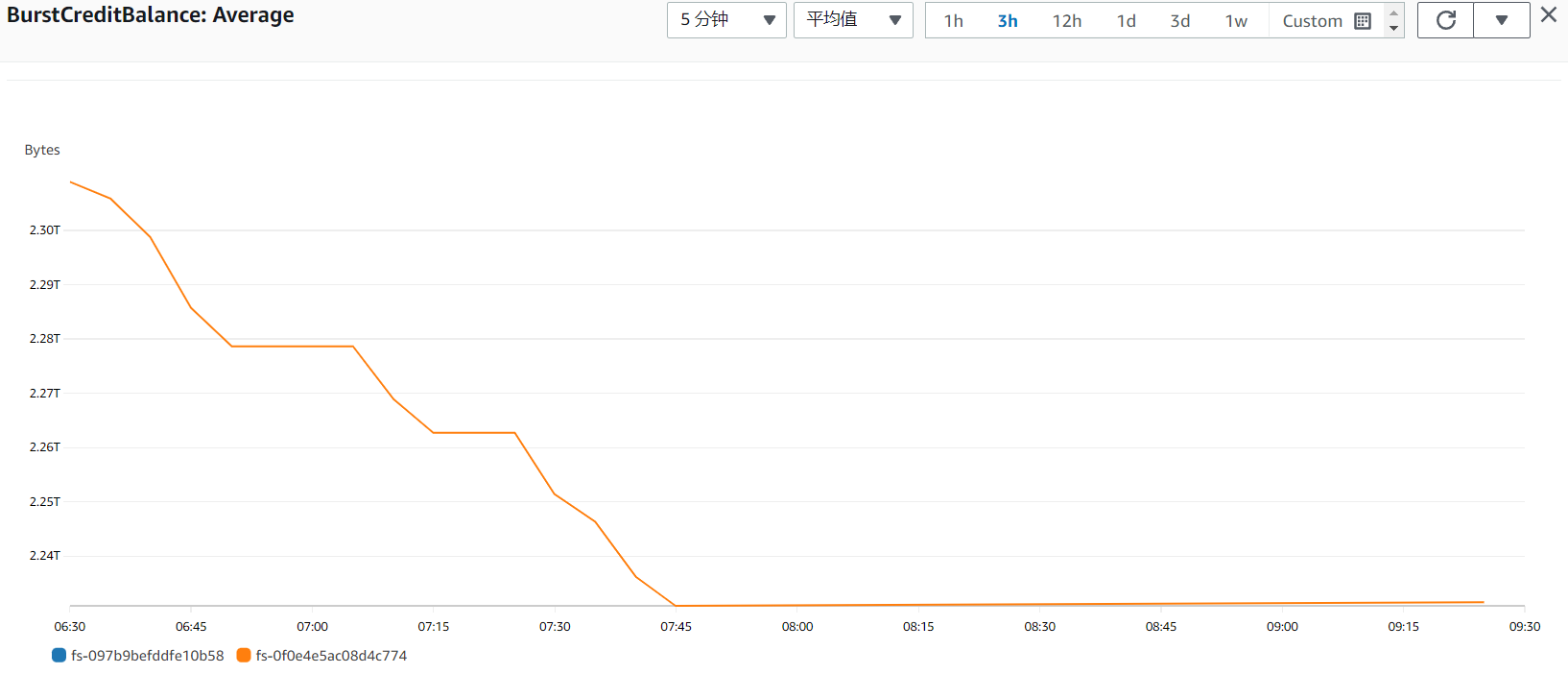
因此,虽然它叫作 突增 积分,但文件系统较小时,由于基线速率太小了,所以基本都在用突增积分,变成一种常态。那问题来了,为什么用了突增积分,吞吐量还是这么少。因为该模式下的吞吐量会被 PermittedThroughput 限制住,只要它不提高,那么吞吐量就一直上不去,IOPS 也就上不去。
PermittedThroughput 的值由文件系统大小决定,其计算方法如下:

其中,红框内的前者就是 PermittedThroughput ,后者就是前文提到的基线速率。最低的 PermittedThroughput 为 105MB(1MiB = 1.048 MB),在 CloudWatch 中可以监控到,如下:
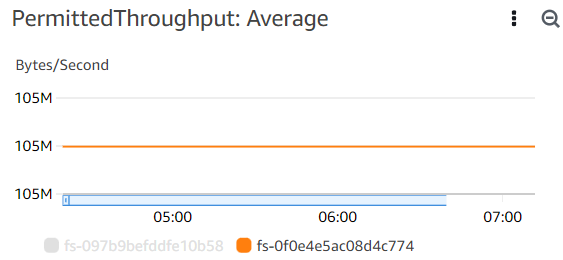
总而言之,如果不提高 PermittedThroughput,那么该模式下 EFS 的吞吐量就上不去。而提高它的唯一办法就是提高文件系统存储量,且要 TB 级的提高才能看到明显的效果,可以说是纯商业级使用了,全是钱。而像官网描述的最高 GiB/s 级的吞吐量,要 10+ TB 才能达到,这在商业使用中很容易做到,但实验中就很难。
成本估计
以首尔地区为例,在不考虑 IA 的情况下,Standard EFS 收费为 0.33 USD GiB/月,One Zone 收费为 0.176 USD,访问不另收费。因为采用的是突增吞吐量模式,所以无需为高吞吐量额外计费,所有的成本来自于文件系统的存储大小。
以一年为时间单位,从两个极端进行估计:
- 压力是波动的,突增积分随时都够用;
- 压力是持久的,突增积分用光了,吞吐量维持在基线速率以下。
以 io2 作为对比,EFS 能够支持的最大吞吐量设为 300MiB/s。io2 采用默认配置,3000 预置 IOPS,大小与 EFS 配置相同。
最优场景
EFS 设置 PermittedThroughput 为 300 MiB/s,则需要 3TB 的存储大小,一年成本为:
- Standard:3000 * 12 * 0.33 = 11880 USD。
- One Zone:3000 * 12 * 0.176 = 6336 USD。
默认 3TB 的 io2 一年成本为:
- 3000 * 12 * 0.1278(存储) + 3000 * 12 * 0.067(预置IOPS) = 7012.8 USD。
最差场景
EFS 设置基线速率为 300 MiB/s,则需要 6TB 的存储大小,一年成本为:
- Standard:6000 * 12 * 0.33 = 23760 USD。
- One Zone:6000 * 12 * 0.176 = 12672 USD。
默认 6TB 的 io2 一年成本为:
- 6000 * 12 * 0.1278(存储) + 3000 * 12 * 0.067(预置IOPS) = 11613.6USD。
总结
如果想要该模式下的 EFS 性能赶上 io2,那么必须要 TB 级别的存储量才行。由于高存储大小下,突增积分的积攒速是比较快的(比如 3TB 下的增速是 150 MiB/s),且大部分应用场景下的大压力都是波动而非持久的,因此可以凭借场景1来预测成本。可以看到,如果存储量为 3TB,One Zone EFS成本是低于io2的。
实际上,AWS 推出 EFS 旨在提供PiB级的共享文件系统,达到这个存储量级之后,EFS 最大写吞吐量能达到 3 GiB/s,每个客户端的写能达到 500 MiB/s,性能是要由于 io2 的。最重要的,io2 的最大容量只有 64TiB,所以 PiB 的文件存储只能用 EFS。
- EFS 适用于 TiB 级甚至 PiB 级的共享存储,但性能不如io2。
- 如果要做到 PiB 级的存储,只能用 EFS。
弹性模式
对于使用弹性吞吐量的文件系统,EFS 会自动向上或向下扩展吞吐量性能以满足工作负载的需求。弹性吞吐量是最佳吞吐量模式,适用于具有难以预测的性能要求的尖峰或不可预测的工作负载,或者驱动吞吐量平均为峰值吞吐量的 5% 或更低(平均峰值比)的应用程序。
由于具有弹性吞吐量的文件系统的吞吐量性能会自动扩展,因此无需指定或配置吞吐量容量来满足应用程序需求。但是需为读取或写入的数据量付费,并且在弹性吞吐量模式下不会累积或消耗突发信用。在所有 AWS 区域中,弹性吞吐量可为每个文件系统驱动高达 3 GiBps 的读取操作和 1 GiBps 的写入操作。
但是我不清楚这个弹性是怎么弹的,测出来的性能依然很弱,可能还是和文件系统的存储大小有关吧,和上一节的 突发吞吐量模式性能差不多。

预置模式
这部分测试直接否定了我前面的所有想法。
预置模式吞吐量理应和文件系统大小无关。为了对应 io2 的效果,这里将预置值设为 300MiB/s,也就是 PermittedThroughput 。如果真的是 PermittedThroughput 限制了吞吐量,那么此时测试结果应该可以达到 200+ MiB/s,但结果并不是这样。

可以看到,整体的 IO 和之前的都差不多,并没有达到 200+ MiB/s。在监控面板中查看吞吐量利用率,如下:
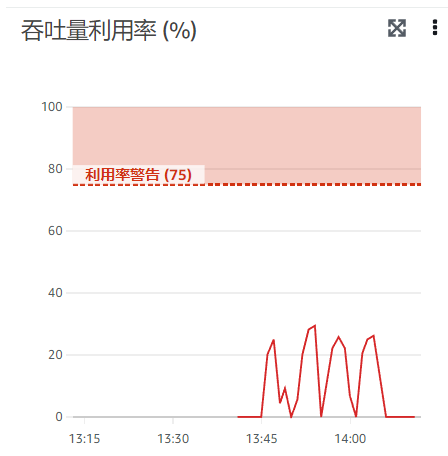
PermittedThroughput 如设置的那样达到了 300 MiB/s,但利用率却很低,峰值也不过 30%。说明这个db_bench 压测的吞吐量并不是受 PermittedThroughput 所限,而是在 EFS 上只能达到 50+ MiB/s。
但是,同样的压测在 io2 上能轻松达到 200+ MiB/s,这不免让我怀疑是 EFS 的性能问题。



